
Data is the basic need for every organization. Every small to big decision is data-backed in organizations today. With multiple data sources and data available in various forms, it becomes important that you collect it responsibly and make sure it is reliable.
Digital Marketing or SEO is no exception from collecting data responsibly. If you extract the data that can help drive your SEO strategy quickly and effectively, it would be icing on the cake with the efforts that you are already putting in.
Despite its substantial potential, the world of SEO is yet to fully uncover the vast opportunities web scraping offers in driving immense traffic and optimizing search engine rankings. In this article, we will see if web scraping is even worth it for SEO or not.
Featured SEO Experts:
Alex Wilson
Andreas Voniatis
Daniel Heredia Mejias
Elias Dabbas
JC Chouinard
Lee Foot
What is Web Scraping?
Web scraping is the process of extracting data from a specific web page. It involves making an HTTP request to a website’s server, downloading the page’s HTML and parsing it to extract the desired data.
Techopedia
Web scraping is the art of extracting relevant data from a source that you think is reliable. There are some techniques & technical terms involved in the process.
- HTTP request is made to access the source and that is granted by the server hosting the webpage.
- The page’s HTML is downloaded and cleaned (parsed) to make the meaning of the collected data.
This collected data can be exported to a spreadsheet to help analyze the data better.
What are the Techniques for Web Scraping?
A) Manual Copy Pasting – The simplest of these techniques is to simply copy the data from the source webpage, and paste it into a spreadsheet to analyze it later. However, this method is error prone and with a huge amount of data to be collected and thus this method is done for usually small tasks.
B) Web Scraping Framework – If you have knowledge of programming languages you can build a web scraper using programming languages like Python, Node.JS, JAVA etc. But again you can scrape small data using these scrapers, however, if you scale the process you would get blocked by the source website in no-time.
When I know which pages that I want to scrape, want specific things or need automation, I use Python and BeautifulSoup.
JC Chouinard
I usually use Python, the library requests is good for web scraping, although Screaming Frog can also be a very effective solution.
Daniel Heredia Mejias
For most jobs I’ll use Screaming Frog with a custom extractor, if it’s something tricky due to JS or something that requires heavy automation I’ll switch to Python. ChatGPT is great for writing small snippets of Python code like this, is such a time saver that it’s not much more effort than using Screaming Frog with a custom extractor.
Lee Foot
C) Web Scraping Tools – For no-coders and non-developers there are tools available like Screaming Frog that can help you to extract data from websites. These tools do screen scraping and extract the data that can be viewed on the source’s webpage. Web scraping tools are mostly used to scrape entire sites and discover optimization opportunities.
When I want to crawl websites without knowing what I’ll learn, I use Screaming Frog. When I want to compare crawls over time, I use cloud-based crawlers.
JC Chouinard
Typically I use Screaming Frog for all my crawling and scraping. But I have also used Google Sheets with XML import functions. If you are careful you can do price monitoring on your competitors with XML Import functions.
Alex Wilson of One Thing Digital
D) Using APIs – Finally, you can use an API. it is an efficient method to extract data at scale and is used by organizations that want data in bulk. There are different APIs available in the market such as DataForSEO or Scrapingdog. They all use proxies at the backend that keep on rotating and hence aren’t detectable at the source website. Although there are specific providers and some of them do provide SEO proxy too.
What’s the Difference Between a Web Scraper and Web Crawler?
Web scraping and web crawling are different terms often confused for one. However, there’s a difference in functionalities. Essentially, a web scraper scrapes a web page while a web crawler crawls a website. This means web scrapers are page-level while web crawlers are site-level.
Web crawlers are essentially web scrapers that allow recursive download. Web crawlers will scrape a web page, extract links, add them to a queue, and then scrape all the web pages in the queue until it is empty, or until a rule is met to stop the crawler.
JC Chouinard
Scraping is extracting certain data from a downloaded HTML page (title tag, h2, meta description, etc.) Crawling is the process of downloading the page, sending it to the scraper and saving to a file. At the same time there are numerous things that a crawler has to handle
Elias Dabbas
Web scraping is extracting structured or unstructured data from a page that you have crawled. Crawling is about page discovery; scraping is about data extraction.
Lee Foot
Web crawling, sometimes called spiders, is a method to index webpages. Google, Bing, Yahoo are some examples of web crawling spiders. There are different types of bots for different crawlers for example, the spider that crawls for Google is known as Googlebot, for Amazon it is Amazonbot.
Web scraping can be used for sentimental analysis. Web scraping is usually used to extract content from a webpage and do something with it. Examples of these are creating a custom tool for natural language processing (NLP) models or creating a custom search engine results page.
What are the Benefits of Web Scraping in SEO?
There are a couple of benefits of web scraping for SEO. Some of them are the benefits that can drive direct impact and others can have an indirect impact on your SEO campaign.
Although technically against Google’s Terms of Service, Web scraping is an indispensable technology that the entire SEO industry’s tools depends on worldwide! The data that comes from web scraping covers many operations from site crawling to simulate search engine interactivity to SERPs data extraction for content optimisation and creation.
Andreas Voniatis of Artios
1. Get Ideas on What Content to Write
Web scraping is a handy tool when planning your content for the upcoming months. By scraping platforms popular in your industry, you can find out which topics are getting attention. This ensures your content stays relevant. It’s like listening in on the industry’s buzz and then sharing your take on those hot topics.
Another smart move is to check out what your competitors are talking about. Scraping the headlines and titles from their blogs can give you a clear picture of what catches a reader’s interest. This not only helps you understand what your audience likes to read but also shows where your content can improve.
Scraping is critical for SEO for a number of reasons. You can scrap your own site to get lists of on page elements (meta titles, descriptions, H1s, etc) for review or optimization. You can scrape other websites (with care and consideration of course) to do competitive research. It gives you the ability to understand entire websites very quickly.
Alex Wilson
There’s also valuable insight by scraping comments, reviews, and feedback. You tap into your audience’s thoughts. You can find out what they like, what bothers them, and the questions on their minds. Using this feedback as a basis for your content ensures it’s not only relevant but also helpful to your readers.
2. Know Content Changes
Web scraping is much more than collecting the data, it can also monitor changes. With intact scraper that is extracting data on regular intervals from your targeted website, you can do the following:
A) Monitor Page Updates – You can set your scraper to regularly check for specific or targeted pages. These pages can be something that is really important or is ranking high. If there’s new content or modifications happening the scraper can alert you the next time it crawls that specific page.
The common use case would be to track product page updates, price changes, or news updates from relevant industry sources or competitors’ sites. JC Chouinard has also used scraping to monitor robots.txt of a website.
I use Web scraping to debug websites, keep track of progress and identify new opportunities. I scrape robots.txt to store its new version whenever it changes.
JC Chouinard
B) Detect Page Not Found 404 Errors – If a page you’re tracking suddenly gets removed or is 404 (error not found), a scraper can notify you. One use case of it can be to track crucial e-commerce sites to check product availability or for content creators to ensure linked resources are still available/accessible.
C) Monitor Site Structure – Websites undergo heavy structural changes. For example, a change in their navigation menu or the introduction of new products or sections. A web scraper can detect these shifts, helping you to stay updated with how new information is being presented or organized.
D) Track Image or Media Changes – Websites have a specific URL assigned to their images, banners or videos that are embedded in their pages. Monitoring changes in them can be helpful for industries where visual content or media updates are frequent.
Since the URL will be changed if any media file is updated, an automated scraper will detect the changes in the URLs of those files. Thus can help you stay updated and relevant to the information.
3. Have Better Keyword Research and Analysis
Web scraping in SEO can also be used to have more effective keyword research. One of these approaches led to a concept called TF-IDF.
TF-IDF means term frequency-inverse document frequency. For a non-technical term it means how frequently a word appears and how rare it is in a large dataset. The goal is to know the important words in a collection of documents. This technical option is an extension of the simple keyword research provided by out-of-box software. It requires planning and resources to do this well.
This approach is a niche option, but it informs SEOs professionals of the page’s search intent. It’s also a more involved use case because TF-IDF leads to machine learning algorithms to achieve a better understanding of these models. With these approaches TF-IDF is great for keyword collection and is used to retrieve relevant information to improve content relevancy.
Some SEO professionals explore this approach in addition to web scraping. Daniel Heredia Mejias used web scraping and created a TF-IDF model. He first scraped pages through Python programming and obtained the important terms from those pages with TF-IDF methodology. After which, he exported it as an Excel file illustrating the keywords and its TF-IDF score.
4. Analyze the Search Engine Results Page
Analyzing Google’s results on the first page can be a goldmine for SEO professionals. This can help you to analyze the search intent and type of content that the search engine would like to present when someone types in relevant keywords.
Scraping Google search results can help you analyze this data with more pace and accuracy. There are ways to do this process of which using a SERP scraper API is one of the best ways. Extracting search results data can give you:
1. Title tags
2. Meta descriptions
3. URLs of the pages that are ranking high
4. You can also extract PAA (People Also Ask) results
You can also scrape search engines to create a custom keyword tracker with Python.
I use web scraping to scrape my favourite search engine and see historical rankings and SERP features for my important keywords.
JC Chouinard
These data points can help to create perfect blog headlines that you would desire to rank for. Seeking the information that is already ranking you can create a skyscraper content to increase your chances of getting top ranking results.
5. Structure Websites Better
A well-structured website not only enhances user experience but also improves search engine visibility. By scraping top-performing websites, you can gain insights into their site architecture. Understanding how these sites organize their content can offer a blueprint for your own site.
This doesn’t mean copying them, but rather getting inspiration and understanding best practices. By analyzing what works for others, you can structure your website in a way that’s both user-friendly and optimized for search engines.
Big websites like ecommerce need this approach benefit from web scraping especially if there’s a website migration. From content changes or detecting ‘not found’ 404 errors to building redirect files, website migrations become less hassle sue to web scraping support.
I do a lot of ecommerce platform migrations, moving companies from Shopify to BigCommerce or Magento to Cart.com Storefront for example. During that process, I run a crawl to pull all URLs and then I can build my redirect files as needed. When I upload those redirects to the new platform, I can take the URL list from the original call, change the domain name to the staging or testing domain, and crawl the list to confirm all URLs show the correct 301 redirects.
Then just before we make the final change, I run another crawl and save it. We make the DNS changes to point the domain name to the new platform, then I crawl the list of URLs from the old website I just got and make sure all URLs are properly redirecting. Finally I run a crawl on the site again to check for any 404 or 500 errors.
Alex Wilson
6. Research on Your Competitors
Web scraping allows you to collect data on the keywords and content your competitors are using for their website. This information can help you understand their SEO strategy and identify potential keywords that you should be targeting.
I use web scraping to do competitive analysis and compare content templates between me and my competitors (e.g. headings, entities, hash, etc.)
JC Chouinard
Daniel Mejias has also used web scraping for competitor analysis. He has extracted metadata as well and mixed it with other SEO techniques like TF-IDF as mentioned above.
Probably another interesting thing about web scraping that I use in my SEO workflows is for competitors analysis. You can extract data from your competitors about the main SEO factors like metadata and content and analyse it together with other techniques like an TF-IDF analysis.
Daniel Heredia Mejias
If you’re optimizing for an ecommerce website, scraping goes a long way especially to get ahead of your competitors. Ecommerce are a goldmine of data for optimization and improving business value.
I have a ton of use cases being an eCommerce SEO. Scraping competitor product names (using the SKU as a common key), Scraping GTIN data from eBay, scraping competitor prices, scraping manufacturer’s Website to create an import file for a CMS to import the product into your own site, scraping competitors (and our own) sitemaps.
Lee Foot
Scraping website responsibly may lead to interesting places especially for ecommerce businesses.
I had an interesting situation where a client was selling proprietary products on a popular marketplace. They had hundreds of products and other companies were piggybacking on their lists, selling counterfeit versions of their products. We were able to get a list of listing URLs and configure a custom scraper to find what listings had multiple sellers at scale. It took a couple hours to configure the scraper and then a couple more hours to run and we were able to find every listing that had a counterfeit seller.
Alex Wilson
Examples of Web Scraping in SEO (with Python)
There are use cases where an SEO specialist can use web scraping to optimize and improve workflows. From extracting simple metadata from the page to creating custom tools.
1. Know External Links From a Page
Yaniss Illoul of Martech with Me built an automation to get external links from a webpage using Python.
He was able to collect a list of links and URLs going outside of the website domain. First Instead of doing this manually (which is prone to errors), you can now use web scraping and check which pages have the least or most external links. As SEO professionals we want to see where we are citing our resources.
2. Get Metadata and Content
Get important metadata from pages faster with scraping and programming languages like Python. With Python, I was able to scrape pages and get important information like the title tag and meta description. Since this code is reusable and scalable, I can use this to enter a list of URLs in bulk instead of going through pages one by one.
Title tag
from bs4 import BeautifulSoup
import requests
def page_title(url):
page_source = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}).text
soup = BeautifulSoup(page_source, 'html.parser')
page_title = soup.find('title').get_text()
return page_titleMeta description
from bs4 import BeautifulSoup
import requests
def meta_description(url):
page_source = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}).text
soup = BeautifulSoup(page_source, 'html.parser')
meta_description = soup.find('meta',attrs={'name':'description'})["content"]
return meta_descriptionHeadings
from bs4 import BeautifulSoup
import requests
def headings(url):
page_source = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}).text
soup = BeautifulSoup(page_source, 'html.parser')
htags = {"H1":[element.text for element in soup.find_all('h1')],
"H2":[element.text for element in soup.find_all('h2')],
"H3":[element.text for element in soup.find_all('h3')],
"H4":[element.text for element in soup.find_all('h4')],
"H5":[element.text for element in soup.find_all('h5')]}
return htagsContent
from bs4 import BeautifulSoup
import requests
def content(url):
page_source = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}).text
soup = BeautifulSoup(page_source, 'html.parser')
paragraph_list = [element.text for element in soup.find_all('p')]
content = " ".join(paragraph_list)
return content3. Autogenerate Title Tags and Meta Descriptions
To take things further, SEO scraping can lead to other fun automations like auto-generating title tags and meta descriptions. I built this tool to scrape pages in bulk. The tool scrapes the page and gets the content, and then generates title tags and meta descriptions by AI based on the content.
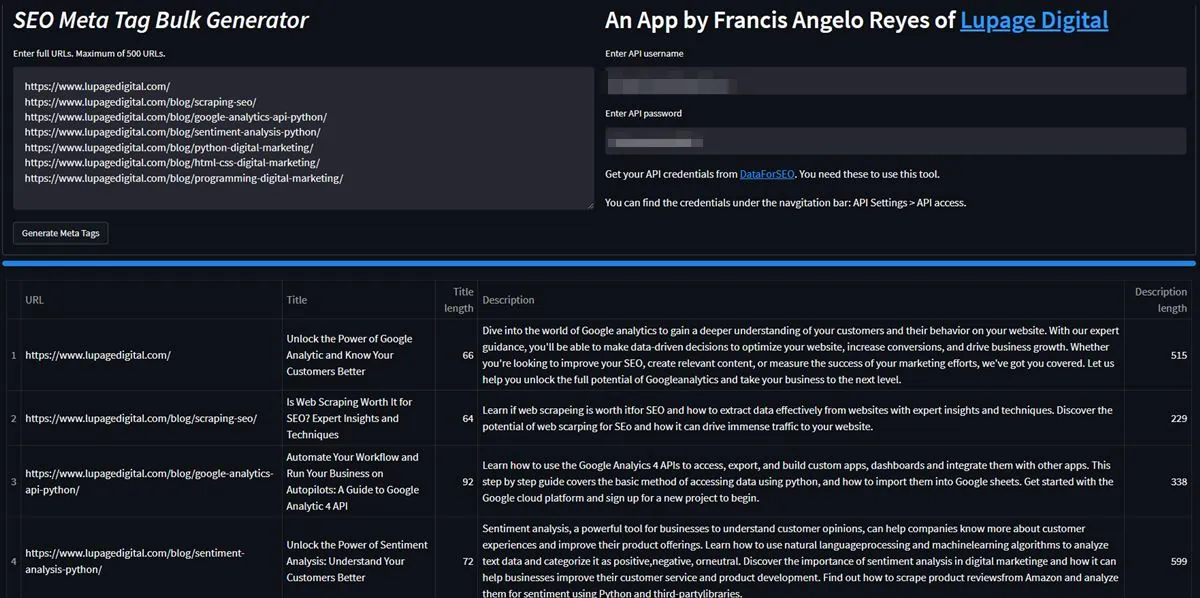
In the past, I had to go to each page then check content then create the titles and descriptions manually. It takes hours. So, I built a tool that does that in scale.
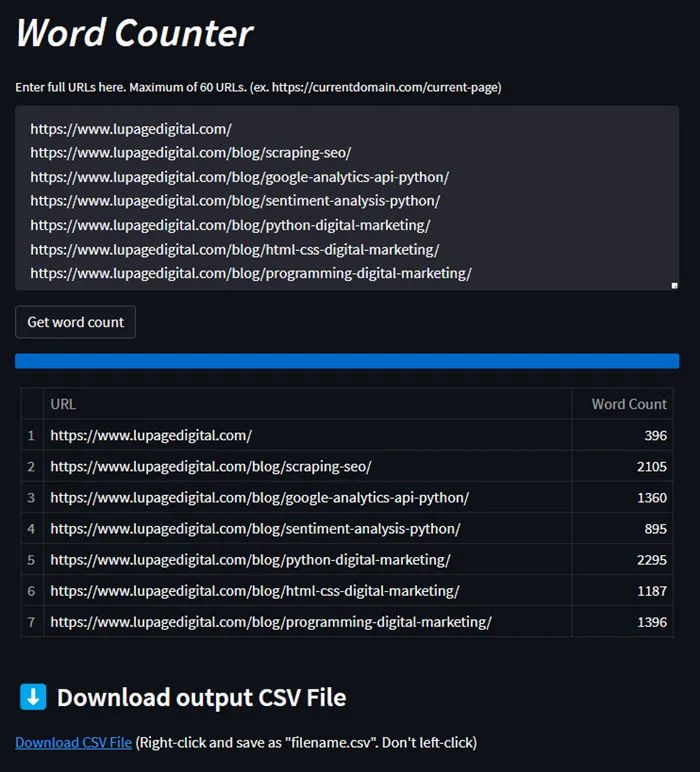
4. Create a Word Counter
Since content from a webpage can be scraped, it can also do word counting. I built a simple word counter based on the page’s <p> (paragraph) tags. On top of that, it can also do word counting for a list of URLs. I personally look at word count to get a glimpse of the content in the search engine results.
5. Develop a Redirect Mapping Tool
In the past, I created a URL mapping tool for SEO redirects. URL redirect mapping is when you point which page becomes the new page in redirection. It’s needed when doing a site migration and it usually involves a spreadsheet with two sets of URLs.
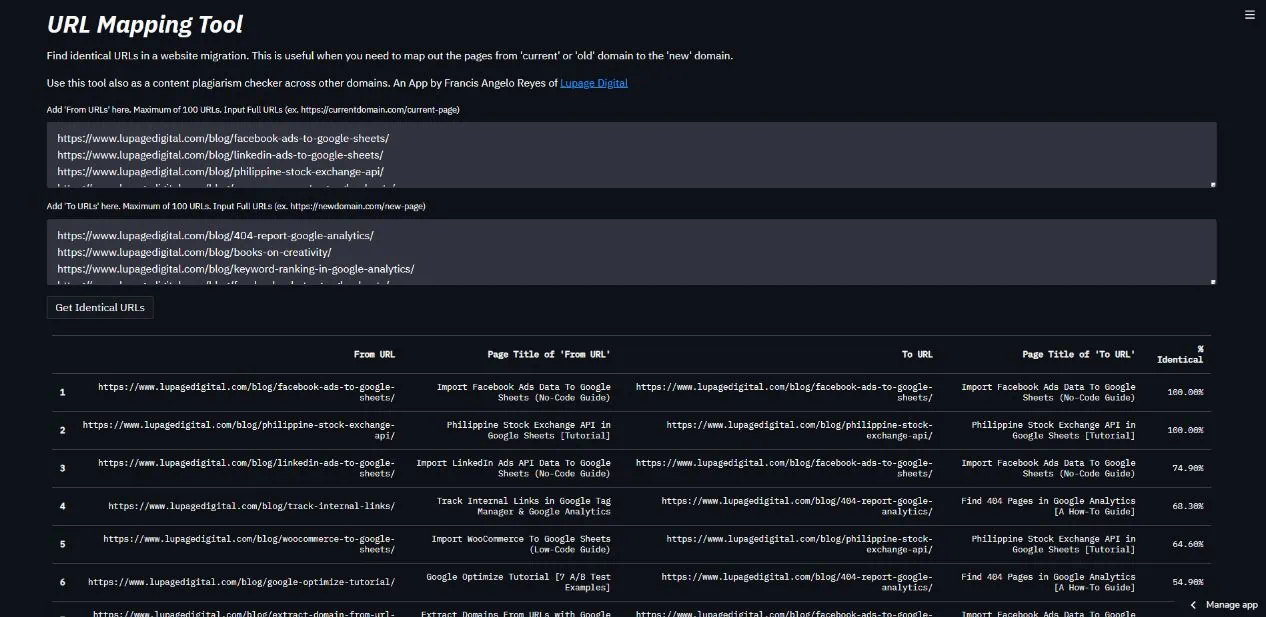
This tool scrapes the webpages, and with Python libraries, performs string matching to know the similarities between pages. This means no need to manually go inside each URL and see which URLs are similar to one another.
6. Build a Custom SERP Analysis Tool
The final test. I created a mini SERP (search engine results page) analysis tool. The benefit from this is it shows the content structure through the <h> tags (heading tags). In this case, it scrapes until H5. When a page doesn’t have that heading, or if a page has other hiccups like JavaScript, it just gives an empty result.
On top of that, I also scraped title tag, meta description, and word count, then display everything on a new page as a tool.
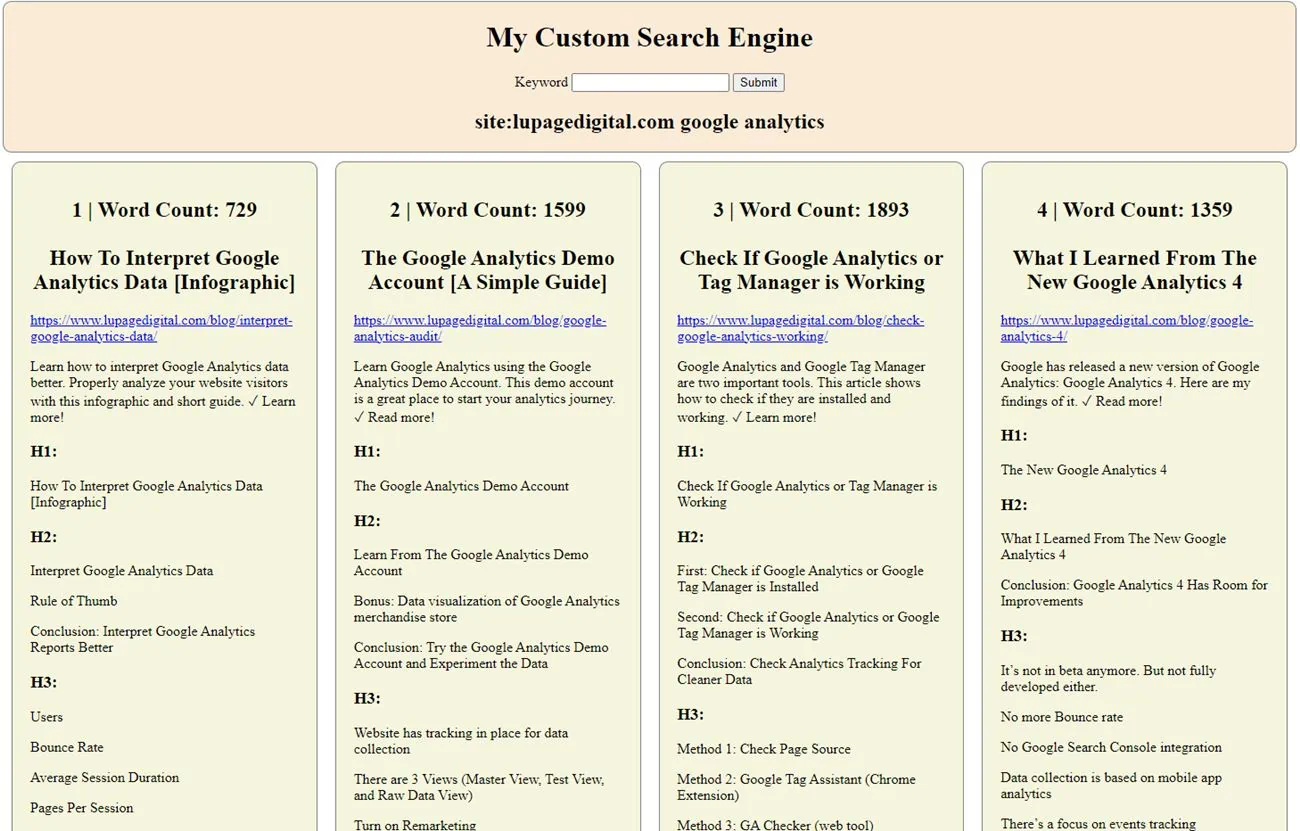
I made this to save time where I need to see content of top results on Google. With this it informs me how to outline the content for an SEO keyword.
7. Create a New Web Scraper and Web Crawler
Elias Dabbas took it even further and created his own SEO crawler: advertools. This Python framework can detect your sitemap and extract a page’s structured data, as well as download robots.txt. It can do word frequency and other URL analysis based on SEO needs.
This framework is perfect for any SEO professional or digital marketer who wants to spill over to data science.
When I started with Data Science I saw a huge gap in terms of special packages (in R and Python) that are for SEO/SEM, and digital marketing in general. There are several packages of course, but most are geared to the developers. I decided to build one, advertools, which among other things, has a powerful SEO crawler (and scraper), that is built with Scrapy, the most powerful crawling framework in Python.
Elias Dabbas
Conclusion: Web Scraping Has a Place in SEO
Web scraping is one of the most underutilized processes that SEO can add to their arsenal. Most popular SEO tools that professionals rely on, like Ahrefs and SEMrush, use web scraping techniques for some of their features. But scraping is an element of data collection that can support those tools.
By learning and using web scraping techniques, SEOs not only can save costs on these tools, but can also be one step ahead of their competitors.
