
“How do I create a 301 redirect map?”
– Frustrated SEO professional
“What is URL redirect mapping?”
Migrating a website site is tedious. Every now and then, there are changes for whatever reason – whether it’s a technical or content change. URLs are different, page titles are different and everything is all over the place. It’s a huge waste of time. Do you wish you could automate this?
Read along and you need have to worry about it anymore.
What is a 301 Redirect?
A redirect is when a URL (Uniform Resource Locator) moves a user from one page to another page inside a website. It’s like the web browser is saying go here since it’s the new location. Now, what’s a 301 redirect? 301 essentially means permanent. A website creates a 301 redirect if it won’t use the old page anymore.
For example:
A: https://olddomain.com/banana-guides
B: https://newdomain.com/banana-guides
Another example:
A: https://samedomain.com/what-are-fruits
B: https://samedomain.com/fruits-guide
If the URL needs to change, an analyst uses a 301 redirect from A to B. 301 redirects often happen in website migration. Whether migrating to a new domain or new URL structure, a marketer needs to keep track of these URLs.
So, how do you map these URLs?
What is URL Redirect Mapping?
URL redirect mapping is when you point which page becomes the new page in redirection. It’s needed when doing a site migration and it usually involves a spreadsheet with two sets of URLs.
Examples:
| From | To |
|---|---|
| https://newdomain.com/banana-guides |
https://olddomain.com/what-are-bananes | https://newdomain.com/ |
| https://newdomain.com/ |
| https://newdomain.com/banana-benefits |
| https://newdomain.com/buy-bananas |
| https://newdomain.com/banana-reviews |
From these sets of URLs, you need to map one page to its identical new page. Then do this method for every page manually.
Why is Redirect Mapping a Major Headache?

Imagine this scenario: the URLs are different. This happens in some cases.
| From | To |
|---|---|
https://olddomain.com/coconuts-guides | https://newdomain.com/guide-to-coconuts |
https://olddomain.com/what-are-coconuts | https://newdomain.com/ |
| https://newdomain.com/coconuts-benefits |
https://olddomain.com/how-to-grow-coconuts | https://newdomain.com/grow-cocon |
https://olddomain.com/buy-coconuts | https://newdomain.com/buy-coconuts |
https://olddomain.com/best-coconuts-today | https://newdomain.com/best-coconuts-today |
https://olddomain.com/coconuts-nearby | https://newdomain.com/23984-coconut-qr2 |
https://olddomain.com/selling-coconuts | https://newdomain.com/selling-coconuts |
The table above is a clean version. But imagine in the beginning you’re given a raw list of URLs. How do you map this? The green color URLs are easy to map. You extract the page path and know they are are identical. By reading the page path, you detect what the content is. This is fine and won’t take too much time.
But what if the page paths are different (the red ones)? Even by one character? Getting the similarities by page path doesn’t work anymore. Yes, you can read the URLs, but that’s prone to mistakes. I had to go inside the URLs and read the content if they’re identical.
But what if you had to read hundreds of URLs manually? That’s a freaking nightmare that it took me at least two days to map them in a spreadsheet. Months after, because of this frustration, I built my own URL redirect mapping tool.
What This URL Redirect Mapper is NOT
This tool is not a redirect checker. It doesn’t check if a URL has a status code 200, 301, 302, or 404. Also, it doesn’t check the redirect chains. You need to look elsewhere if you need to count how many redirects a page has.
This tool is also not a URL visualizer. This tool crawls and analyzes a set of URLs. But it won’t give you a visualization of the website structure in either trees or nodes.
This tool is also not a URL redirect generator. It doesn’t generate the redirection code that’s entered to the .htaccess file.
How to Build a Free Redirect Mapping Tool
You may use other programming languages. For this one, it’s Python. I recommend using a Jupyter notebook as there is a DataFrame involved. But you may use any text editor like Visual Studio Code or Atom if you prefer.

In the end, I’m glad about how the tool turned out. I wish the redirect mapper was invented already when I was doing site migrations. That said, let’s get into it. To Python developers reading this article, have mercy on the code if it’s not optimized. 😅
1 – Import Libraries
from bs4 import BeautifulSoup, SoupStrainer
from polyfuzz import PolyFuzz
import concurrent.futures
import csv
import pandas as pd
import requestsThese are the libraries to import for this tool to work. Install these libraries on your machine via pip install. bs4 is for content scraping. PolyFuzz is for content matching. concurrent.futures is for fast processing. csv for exporting to a spreadsheet. pandas for DataFrames. requests for content scraping.
2 – Import URLs
with open("<YOUR FIRST .TXT FILE>", "r") as file:
url_list_a = [line.strip() for line in file]
with open("<YOUR SECOND .TXT FILE>", "r") as file:
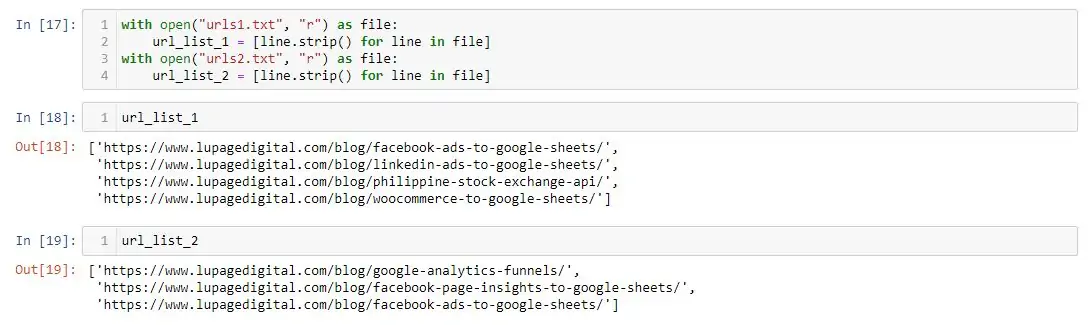
url_list_b = [line.strip() for line in file]Next is importing two text files the contains the list of your URLs. Create the text files on your computer in the same directory or folder that houses the code.
The URLs are imported to the code as reusable Python lists. Note that the code above are for .txt files. And don’t forget to change <YOUR .TXT FILE> to your actual files. You may also use a CSV file.
3 – Create a Content Scraper via BeautifulSoup
def get_content(url_argument):
page_source = requests.get(url_argument).text
strainer = SoupStrainer('p')
soup = BeautifulSoup(page_source, 'lxml', parse_only=strainer)
paragraph_list = [element.text for element in soup.find_all(strainer)]
content = " ".join(paragraph_list)
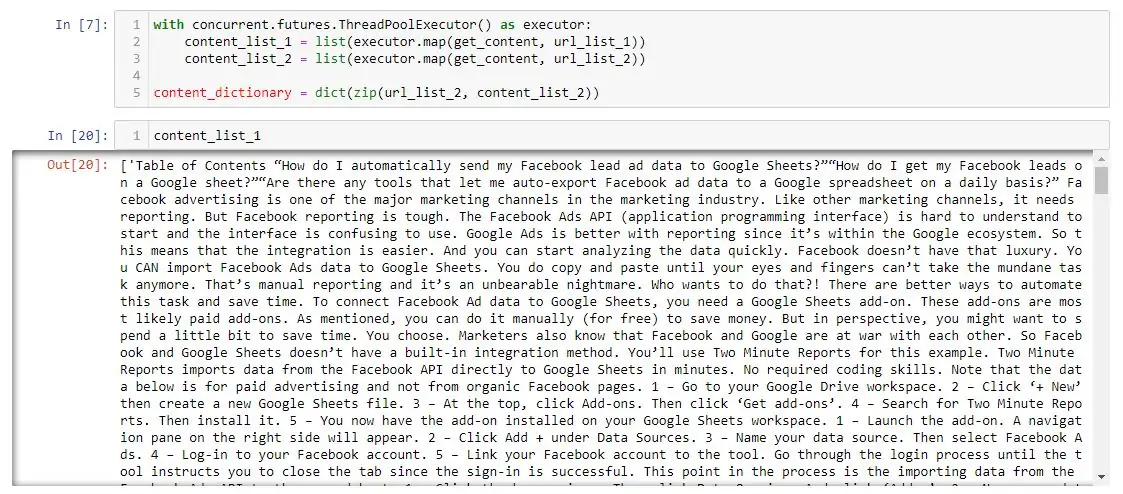
return contentNext is create a scraper function to acquire the content of the pages. The content of the pages is used later on to do the matching. In this code, the tag to scrape is the <p> paragraph tag. SoupStrainer hastens the processing since it scrapes the <p> tag only. No results are returned at this point.
4 – Scrape the URLs for Content
with concurrent.futures.ThreadPoolExecutor() as executor:
content_list_a = list(executor.map(get_content, url_list_a))
content_list_b = list(executor.map(get_content, url_list_b))
content_dictionary = dict(zip(url_list_b, content_list_b))Next is actually scraping the URLs and extracting the content. URL List A creates Content List A while URL List B creates Content List B. The concurrent library processes the code quicker. Concurrency means that the program isn’t waiting to finish executing a code before executing the next code.
5 – Get Content Similarities via PolyFuzz
model = PolyFuzz("TF-IDF")
model.match(content_list_a, content_list_b)
data = model.get_matches()Next is using PolyFuzz to match the content. The chunk of the algorithm relies on this library or package. Essentially, it matches Content List A and Content List B that were created earlier. After this point, it creates the Similarity metric, which is the most important data. The Similarity metric is a percentage.
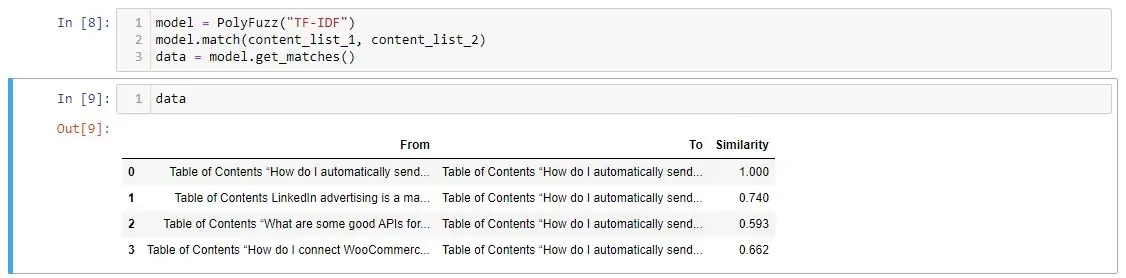
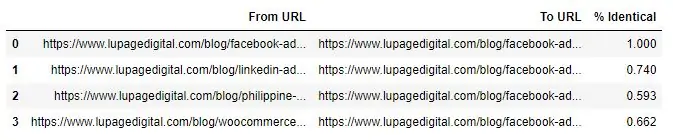
The result is a DataFrame containing three columns: “From”, “To”, and “Similarity”. If you look closely, the results are the content, which is what we need. But we need to map the content results back to the entered URLs.
6 – Map Similarity Data Back To URLs
def get_key(argument):
for key, value in content_dictionary.items():
if argument == value:
return key
return key
with concurrent.futures.ThreadPoolExecutor() as executor:
result = list(executor.map(get_key, data["To"]))Next is mapping the results from PolyFuzz back to the URLs. In the end, the results should display the URLs and not the content even though we used the content for matching. Same as before, this part of the code uses concurrency to process quicker.
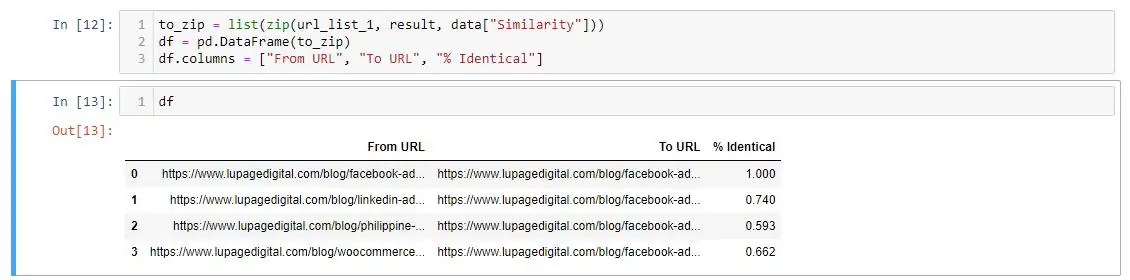
7 – Create a DataFrame For Final Results
to_zip = list(zip(url_list_a, result, data["Similarity"]))
df = pd.DataFrame(to_zip)
df.columns = ["From URL", "To URL", "% Identical"]Next is forming a DataFrame, which is like a spreadsheet. At this point, we also label the columns for information. The third line df.columns is arbitrary and you can name them whatever you like as the columns. The DataFrame is sorted by the newly created “% Identical” column.
9 – Export To a Spreadsheet
with open("<YOUR .CSV FILE>", "w", newline="") as file:
columns = ["From URL", "To URL", "% Identical"]
writer = csv.writer(file)
writer.writerow(columns)
for row in to_zip:
writer.writerow(row)This is the final piece of the puzzle, which is exporting the data to a CSV file. Create a CSV file in the same directory that houses the code and the URL text files. Don’t forget to change <YOUR .CSV FILE> to your CSV file and its location folder.
The spreadsheet should be the same with the DataFrame created above. It should have columns “From URL”, “To URL”, and “% Identical” also. The second line columns is arbitrary and you can name them whatever you like as columns. Exporting to a spreadsheet is an optional step so this depends on your use cases.
Viola! Hopefully, it works on your end.
Even if you don’t have a site migration project, you can use this as a plagiarism checker. Since it takes any set of URLs, you enter any page and see its similarities. It’s fun! 😃 At this point, it’s up to you to share the tool with others or deploy it as an app. Add other data like the page title or word count for each URL if you know more advanced Python.
Try the URL Redirect Mapper in Action
I deployed my version of the tool and hosted it on Streamlit. You can access the app through the internet. https://url-mapping.herokuapp.com/
Benefits of Redirect Mapping for Digital Analysts
Using a URL redirect mapping tool offers many benefits for SEO migration consultants, particularly in managing the complexities of website migrations and ensuring seamless user experiences. Here are some key advantages:
Streamlined Redirect Management
A URL redirect mapping tool simplifies the process of managing redirects during an SEO migration. By allowing consultants to easily create and visualize redirect maps, they can ensure that all old URLs point correctly to their new counterparts, minimizing the risk of broken links and 404 errors in the transition.
Preservation of SEO Performance
Consultants can maintain search engine rankings throughout the migration process by efficiently mapping redirects. This ensures that traffic from external links continues to flow to the appropriate pages, reducing the potential for lost rankings and organic traffic.
Data Tracking and Analysis
URL redirect mapping tools can often integrate with analytics platforms like Google Analytics, allowing GA4 consultants to track the performance of redirected URLs. This ability to monitor user behavior post-migration allows for quick identification of any drop in traffic or engagement, facilitating immediate corrective actions if necessary.
Enhanced Collaboration
These tools typically include features that enhance collaboration among team members. SEO migration and GA4 consultants can work together more effectively by sharing redirect maps and insights, ensuring that all stakeholders are aligned on the migration strategy and its potential impact on tracking and analytics.
Minimized Risk During Migration
By providing a clear overview of all redirects, these tools help mitigate risks associated with website migrations. Consultants can identify potential issues in advance, allowing for proactive adjustments and ensuring that the transition is as smooth as possible for both users and search engines.
Conclusion: Map URL Redirects with Less Pain
SEO professionals know the pain of URL mapping. There are too many variables and it’s tough to keep track of them all. An automatic redirect mapping tool simplifies this process. Detect URLs and their similarities with an instant preview. Save time so you can focus on what matters most: your site migration.
